



VectorCache: Streamlining LLM Query Performance
Optimizing AI Efficiency: A new way to enhance LLM Performance & Reduce Inference Costs with smart semantic caching

In the burgeoning field of artificial intelligence, the cost and speed of processing large language model (LLM) queries are critical considerations for developers and businesses alike.
This is where vector-cache, a Python library designed for semantic caching, comes into play. It enhances LLM query performance, making it faster and more cost-effective—a boon for AI-driven applications, especially RAG.
What is Vector Cache?
VectorCache is a solution aimed at optimising the use of large language models by caching responses based on semantic similarity. This approach helps in significantly reducing the latency and operational costs associated with LLMs.
Key Features and Benefits
Faster Responses
VectorCache decreases the latency of responses by storing previously computed answers from LLMs. When a new request comes in, the system checks if an answer that is semantically similar to the request has been cached, allowing for quicker feedback.
Reduced Costs
By minimising the number of direct queries to LLMs, VectorCache helps save on usage costs. This is particularly advantageous for applications that require frequent querying to LLMs.
Enhanced Efficiency
Think of VectorCache as a more nuanced version of Redis; it recognises not just exact matches but also queries that are semantically similar. This feature is especially beneficial in domains where queries tend to revolve around specific topics or fields.
Application Layer Integration
This is one very intentional design decision I took, to make vector-cache easy to integrate at application layer, it does not extend or wrap existing LLM library functions and can instead simply work off the ‘query’ string only.
Getting Started with VectorCache
Prerequisites
Before diving into VectorCache, ensure that your system has Python version 3.9.1 or higher. You can check your Python version by running python --version in your command line.
Installation
To avoid any hiccups during installation, it's a good idea to upgrade pip using the following command:
The easiest way to get started is by using the official pip package.
pip install vector-cacheOr you ca clone the git repository on your machine and build around it.
git clone git@github.com:shivendrasoni/vector-cache.git
cd vector-cache
python -m venv venv #(optional)
python -m pip install -r requirements.txtFor a hands-on introduction to VectorCache, explore the examples provided in the 'examples' folder of the library. A dedicated pip package is also in the pipeline and will be available soon.
Components of VectorCache
Embedding Models: Facilitate similarity searches through various embedding APIs.
Cache Storage: Stores LLM responses for future retrieval based on semantic matches.
Vector Store: Identifies similar requests using the input request's embeddings.
Cache Manager: Manages cache storage and vector store operations, including eviction policies.
Similarity Evaluator: Determines the similarity between requests to ensure accurate cache matches.
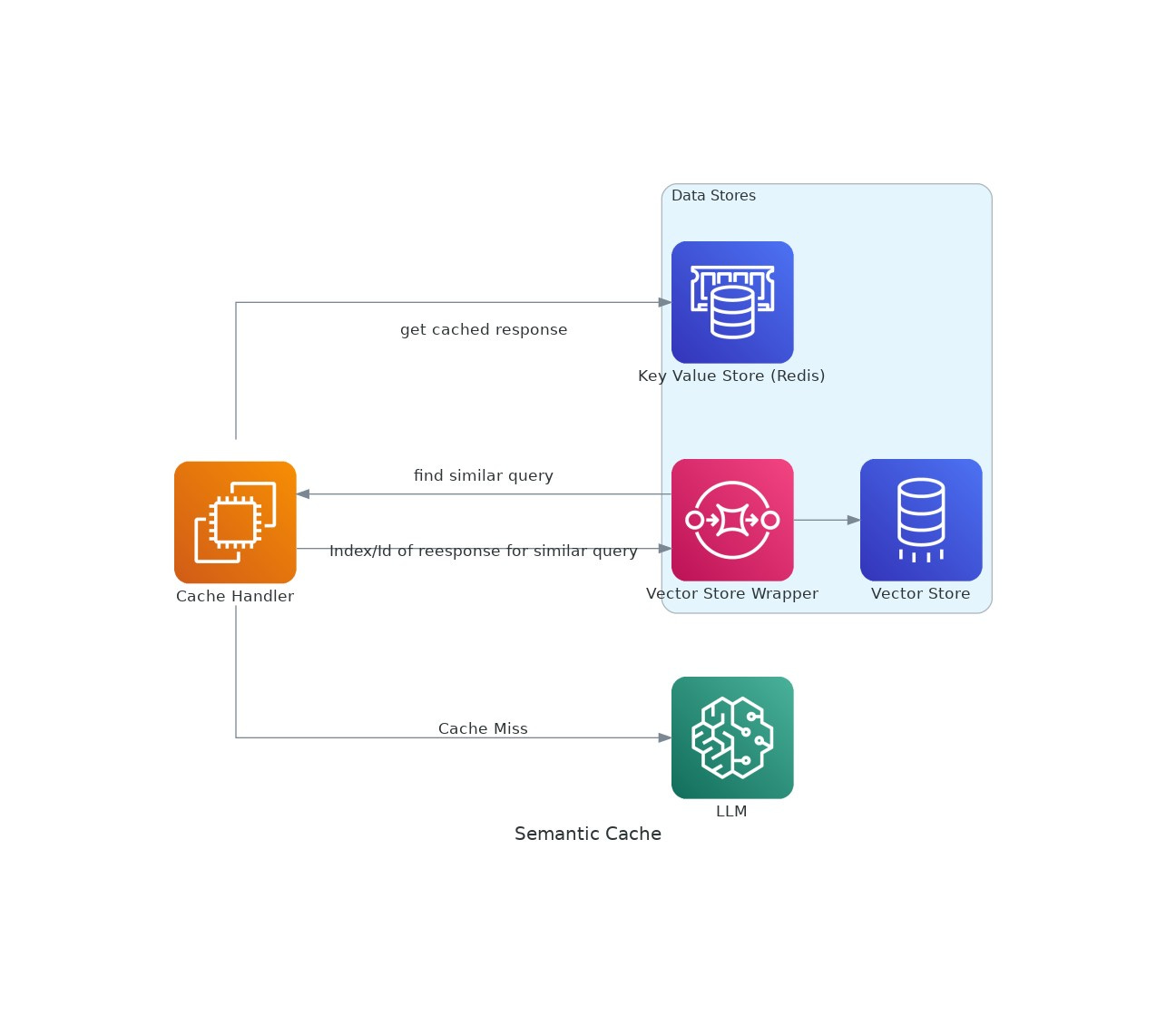
How it works:
The idea is very simple, a request to the LLM comes in, we see if a similar query was made previously? If yes, we respond with the previous response, else we send the request to the LLM and then capture its response.
To detail it out a bit more:
A query has to be sent for inference to an LLM.
We vectorise the query and try to find the most similar query in our vector database using cosine similarity (upto a threshold).
To vectorise, we use one of the embedding models (eg. openai embeddings, SentenceBert, Anthropic etc)
Vector store is a special kind of database, which can store vector representation of text chunks
Caching is any fast access key value store. This can be an in memory db like Redis or a persistent store like Mongodb, couchbase etc.
If a similar document was found, we select the relevant doc from our cache (or database), the ID of the document is the value of the record searched above via vector similarity.
If a response was found in the cache we return it, else, we send the query to the LLM and then cache it back into the cache.
How You Can Contribute
Interested in shaping the future of vector-cache? Contributions are welcome! Check the contribution guidelines on the GitHub repository to get started.
All the major components of the package use an Interface, which must be implemented for the library to work. They can be found in the individual directories.
Future Scope
Our work here is far from over and has a lot of scope to be improved. Few ideas which I have to improve this would be:
Add cache invalidation and TTL support
Add more embedding models (Anthropic, Gemini, Nomic etc)
Add more vector store support (Qdrant, Mongodb etc)
Account for various LLM params (like temperature) in cache strategy.
Add async caching strategy.
Conclusion
VectorCache represents a significant advancement in the field of AI technology by enhancing the efficiency and effectiveness of LLM applications. It stands out by not only reducing operational costs and latency but also by providing a sophisticated mechanism to handle semantically similar queries. For developers and enterprises leveraging LLMs, VectorCache offers a compelling solution that marries cost-efficiency with high performance.
Embrace the future of AI with VectorCache—where speed meets efficiency!